
9·
6 days agoYou’re one of the founding members of the greater Seattle area polycule, aren’t you?
You’re one of the founding members of the greater Seattle area polycule, aren’t you?

If you’re somewhere in the world that has a TJ Maxx/TK Maxx or similar, go buy their random products that are on sale. Not all are winners, but if you change up your products and just experiment, you’ll find something you like.
I have long wavy hair, and right now I’m on a Shea Moisture curl and shine kick, but before then it was the Verb Ghost line of products for a long time.
Don’t sleep on after shower crap, either. My hair has been really dry lately, so I’ve been using a leave in conditioner by Shea, too (now discontinued, sadly). In the rotation is also the Verb Ghost Oil, and some random peptide leave in. JVN (Johnathon Van Ness) also has some excellent products, but we haven’t found them on sale in awhile.
I don’t use all the after shower products at once, but each has their use. Once you get a feel for what you’re going for, it’s like having a shelf full of tools.
And if you got a beard, well… use something and tell me if you figure out what works, because I still can’t figure that out. My hair looks great and my beard looks like it got lost in the desert.

A base plate that’s got a spring under it, except for a little nub that pokes the power button.
Terrible if you live in earthquake-prone areas.
Wait. Are we describing a bump stock for your computer?
If I had one of those in my living room, my house would collapse.
Shirley you’ve heard of absurdist humor?
You say “Not even close.” in response to the suggestion that Apple’s research can be used to improve benchmarks for AI performance, but then later say the article talks about how we might need different approaches to achieve reasoning.
Now, mind you - achieving reasoning can only happen if the model is accurate and works well. And to have a good model, you must have good benchmarks.
Not to belabor the point, but here’s what the article and study says:
The article talks at length about the reliance on a standardized set of questions - GSM8K, and how the questions themselves may have made their way into the training data. It notes that modifying the questions dynamically leads to decreases in performance of the tested models, even if the complexity of the problem to be solved has not gone up.
The third sentence of the paper (Abstract section) says this “While the performance of LLMs on GSM8K has significantly improved in recent years, it remains unclear whether their mathematical reasoning capabilities have genuinely advanced, raising questions about the reliability of the reported metrics.” The rest of the abstract goes on to discuss (paraphrased in layman’s terms) that LLM’s are ‘studying for the test’ and not generally achieving real reasoning capabilities.
By presenting their methodology - dynamically changing the evaluation criteria to reduce data pollution and require models be capable of eliminating red herrings - the Apple researchers are offering a possible way benchmarking can be improved.
Which is what the person you replied to stated.
The commenter is fairly close, it seems.
I’ve turned off my voicemail with my cell carrier, and send all unknown numbers to voice mail.
It’s a peaceful life.
Well. That’s it. Get the flamethrowers. Time to burn down the Amazon.
No. Not the one that’s already burning. The other one.
Well, I just realized I completely goofed, because I went with .arpa instead of .home.arpa, due to what was surely not my own failings.
So I guess I’m going to be changing my home’s domain anyway.
For only way more time and money, you can buy a zigbee smart plug and a vendor agnostic zigbee hub flashed with FOSS, or you can buy a esp-based board, wire it up with a relay, and flash it with something like esphome.
Sure, it’s way more money and hours of work (cumulatively), but it won’t lose support!
My wife shared this with me yesterday, but I didn’t see it:
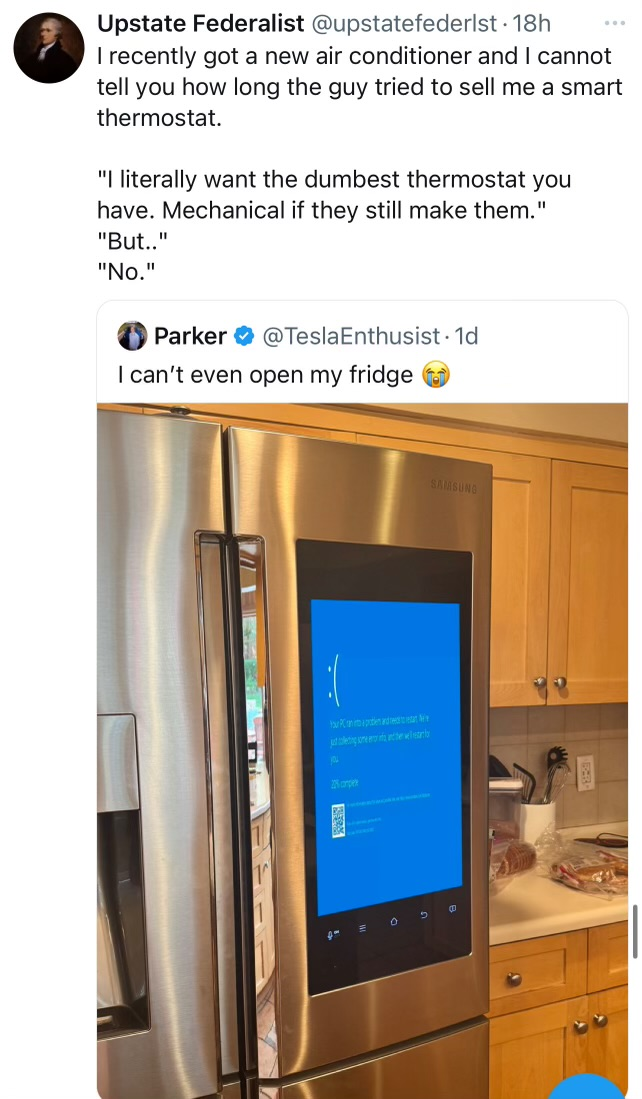
Somebunny is gonna learn those things aren’t windows-based today!
The other commenter on this pointed out that I should have said crisis management rather than disaster recovery, and they’re right - and so were you, but I wasn’t thinking about that this morning.
That’s a really astute observation - I threw out disaster recovery when I probably ought to have used crisis management instead. Imprecise on my part.
Ah, you’re right. A poor turn of phrase.
I meant to say that intel brands their IPMI tools as AMT or vPro. (And completely sidestepped mentioning the numerous issues with AMT, because, well, that’s probably a novel at this point.)
I think we’re defining disaster differently. This is a disaster. It’s just not one that necessitates restoring from backup.
Disaster recovery is about the plan(s), not necessarily specific actions. I would hope that companies recognize rerolling the server from backup isn’t the only option for every possible problem.
I imagine CrowdStrike pulled the update, but that would be a nightmare of epic dumbness if organizations got trapped in a loop.
Honestly kind of excited for the company blogs to start spitting out their disaster recovery crisis management stories.
I mean - this is just a giant test of disaster recovery crisis management plans. And while there are absolutely real-world consequences to this, the fix almost seems scriptable.
If a company uses IPMI (Called Branded AMT and sometimes vPro by Intel), and their network is intact/the devices are on their network, they ought to be able to remotely address this.
But that’s obviously predicated on them having already deployed/configured the tools.
Literally last week my wife noticed one while out and remarked “I can’t believe they’re still around.”
I just sent the article to her with the caption “You did this!”
Anyone else think this was the “taking a selfie using a silly object” meme at first?
I have ADHD you glorified staple.